
5��13�գ�С����ʽ����——Xiaomi OneVL��һ��ʽDZ�ռ������Ӿ�������ܡ���ģ����ҵ������ʵ��VLA������ģ�͡�DZ�ռ������ȶ������·�ߵ�ͳһ���ھ߱�XLAģ��ǿ�����������Ļ����ϣ�����������������ٶȺ;��ȣ��ھ����ϳ�Խ��ʽCoT�����ٶ��϶���“����”Ԥ���DZ�ռ�CoT������
С�������ijƣ����ǽ�Xiaomi OneVL��ģ��Ȩ�غ�ѵ������������ȫ�濪Դ����ȫ���߹�ͬ�ƶ��Զ���ʻ�Ľ����͵������������ţ��ⲻֻ��һ�ζ�XLA�Ĺ��ܲ��䣬���Ƕ�XLA����·����“DZ�ռ�����”������һ�����̽����
���죬С�����з��Ŷ���Latent CoT�Ļ����Ͻ�һ��̽���Զ���ʻ��ģ���е�DZ�ռ��������⣬��ʽ�Ƴ�——Xiaomi OneVL��һ��ʽDZ�ռ������Ӿ�������ܡ�
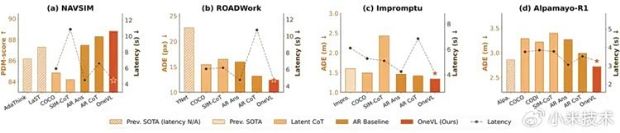
��ΪXLA�ܹ���Latent CoT�������״�ѧ����֤��Xiaomi OneVL�����ھ����ϳ�Խ��ʽ˼ά�������ٶ��϶���“����”Ԥ���DZ��������������ʵ����VLA������ģ�͵�ͳһ��

ͨ��“�������� + �Ӿ�δ��Ԥ��”��˫�ؼල��Xiaomi OneVL���ɽ�����������ģ�͵�δ��Ԥ������ͳһ��latent reasoning�У�Ϊ�Զ���ʻ��ģ��̽����һ���µľ���—Ч��ƽ��·����
�����������˵��Xiaomi OneVL��һ����֤��XLA�ܹ�����ļ���DZ��������������ʵ����ĸ�����ʻ����ֻҪ�������£���Ҫ���������Ԥ��δ������������ʱ������ɸ��������ߡ�
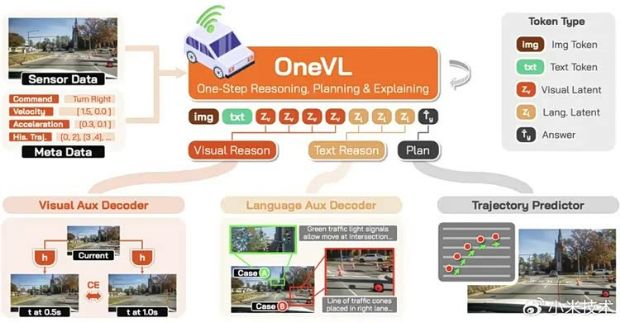
��ȥ��VLA������ģ�����Զ���ʻ����������Զ����ļ���·�ߣ�VLAרע�����ⳡ���������ʻ����������ģ��רע��Ԥ��δ���������ݱ䡣Xiaomi OneVLͨ��DZ�ռ��������״ν�����ͳһ��ͬһ����С�
���ĺ��Ķ����ǣ��Զ���ʻҪѹ���ģ���ֻ���������������Ƕ�δ������仯�����⡣ ��ʻ�������������ģ�����ֻ��“ǰ���г�”“��·��խ”�������������������dz����˶�����·���Ρ��ϰ����ݱ��ʱ�������Ϣ��ѹ�����ԣ�������ǡǡ����ؼ�������ṹ����ѹ����“��δ���Ӿ������Ԥ��”���ű���������������ʻ����Ķ�����
������һ���죬Xiaomi OneVL �������ؼ�����������˵����ģ�����Լ���“�ڲ�����”˼��������ѧ��Ԥ��δ�����桢����������������ѹ����һ����ɡ�
�ں��Ǹ�֪��������滮�Ķ���������ϣ�Xiaomi OneVLȫ��ˢ����DZ�������������������ޡ�
ͬʱ��Xiaomi OneVL��Ϊģ�;����ṩ���Ժ��Ӿ�˫ά�ȵĿɽ�����——����������˵��“Ϊʲô������”��Ҳ����Ԥ�⻭��չʾ“�������ᷢ��ʲô”����XLA�����“����������”�����������䵽�˿���֤���ɽ��͵Ĺ���ʵ���С�

С�ٷ��ƣ�Xiaomi OneVLģ�����������ȫ�濪Դ����ӭȫ�������о���Ա��ͬ���룬̽���Զ���ʻ��ģ�͵������ܡ�















